INTEGRATION OF DATA:
Often, the data needed to create meaningful model may reside over multiple sources such as flat text files (.txt, .csv, .tab), hyper text markup language (.htm, .html), Microsoft excel worksheets (.xls, .xlsm, .xlsb, .xlsx), Microsoft Access (.mdb, .accdb), SAS datasets (.sas7bdat) and hence the key is to ensure successful and reliable data import process. Data modeling softwares such as SAS Enterprise Guide will provide you advanced features to import data from myriad of sources very conveniently without diving into coding details.
 |
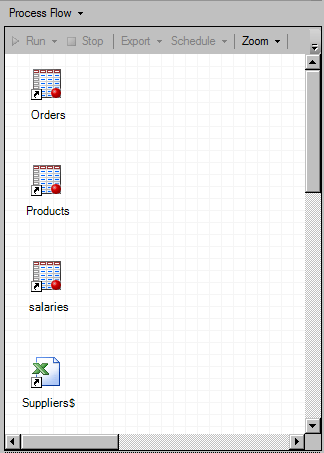
| Data Import example of SAS Datasets and Microsoft Excel worksheet |
In the above process flow snapshot, the first three icons denoted by red ball represent SAS datasets named Orders, Products and salaries. The fourth green X icon represents Microsoft Excel worksheet named Suppliers.
During the import wizard process, close attention must be paid to the nature of the data being imported such as the field's name, length, format, data type, informat, label and by all means take advantage of the features provided to ignore certain fields if they are irrelevant to the data model in order to optimize the design in terms of memory requirements.
It is a good practice to open each of the imported dataset and perform quick data examination of sample observations so that there is confidence in proceeding with next steps involved in data modeling.